
一.简介
特征哈希将一组分类或数字特征投影到指定维度的特征向量中(通常远小于原始特征空间的特征向量)。这是通过使用哈希技巧,将特征映射到特征向量中的索引来完成的。
二.代码实现
package org.com.tl.spark.mllib import org.apache.log4j.{Level, Logger} import org.apache.spark.ml.feature.FeatureHasher import org.apache.spark.sql.SparkSession /** * Created by zhen on 2020/11/27. */ object FeatureHasherExample { /** * 设置日志级别 */ Logger.getLogger("org").setLevel(Level.WARN) def main(args: Array[String]) { val spark = SparkSession.builder() .appName("FeatureHasherExample") .master("local[2]") .getOrCreate() val dataset = spark.createDataFrame(Seq( ("1", 1.2, true, "Spark"), ("2", 3.4, false, "Spark"), ("3", 5.6, true, "Flink"), ("4", 7.8, false, "Flink") )).toDF("index", "number", "boolean", "technology") val hasher = new FeatureHasher() .setInputCols("index", "number", "boolean", "technology") .setOutputCol("features") val featurized = hasher.transform(dataset) featurized.show(false) spark.close() } }
执行结果:
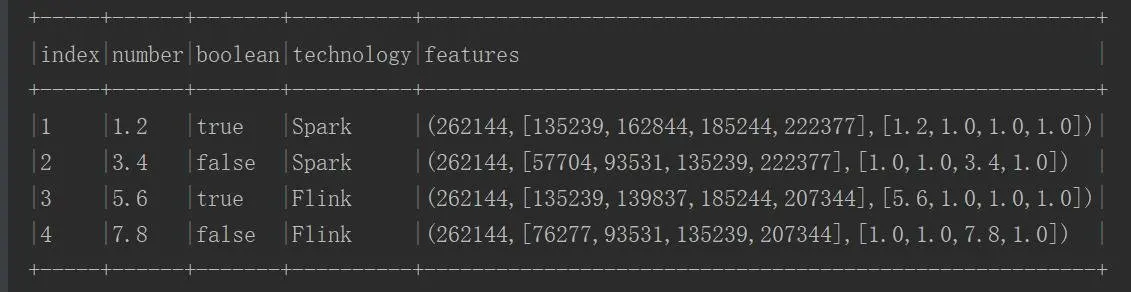 ...
...
看到这个结果大家可能是比较懵逼的,它不像一些算法,把特征向量映射为一个稀疏矩阵,通过填充指定位置的数值来对特征进行正则化;FeatureHasher通过使用Hash映射,把特征映射为Hash值来实现的;大家看源码!
三.源码分析
从代码上可以看出,特征哈希首先new了一个FeatureHasher()对象,然后调用transform方法:
进入FeatureHasher源码:
 ...
...
从源码上可以看出,该算法是Spark2.3版本的新特性,在使用时要注意,别在低版本中使用。下面进入transform方法中:
后续会多次使用该函数:
进入FeatureHasher的伴生对象中的murmur3Hash方法中,首先看到的是seed随机种子,该参数来自HashingTF:
FeatureHasher在多列上运行。每列可以包含数字或分类特征。列数据类型的行为和处理如下:
进入其中一个hashInt函数探究一下具体的代码逻辑,需要进入类Murmur3_x86_32
public static int hashInt(int input, int seed) { int k1 = mixK1(input); int h1 = mixH1(seed, k1); return fmix(h1, 4); }
可知该函数使用另一个函数mixK1对输入input进行处理,mixK1代码如下:
private static int mixK1(int k1) { k1 *= C1; k1 = Integer.rotateLeft(k1, 15); k1 *= C2; return k1; }
其中C1、C2都是常数:
...而Integer.rotateLeft(k1, 15)的代码逻辑如下:
...其实就是按位向左平移15。通过以上的代码梳理,可以看出,要生成一个特征的hash映射,首先需要判断其类型,不同的类型采用不同的处理逻辑,其次使用murmur3Hash函数将不同类型的特征数据导入不同的方法中,最后使用Murmur3_x86_32类中的方法对特征数据做乘积,位平移等处理逻辑实现特征数据Hash化。
最后来看一下开始时的执行结果,前面的特征数据:
...主要看一下后面生成的hash映射:
...看transform函数:
...使用的就是嵌入hashFunc的hashFeatures自定义函数!
